C++ の Short String Optimization(SSO)
C++ の std::string は、C++ を学ぶときに最初期から最もよく使う標準ライブラリの 1 つです。学習では「string はコンテナ(container)で、だいたい std::vector<char> のようなもの」と理解することが多いと思います。
std::string の中身がどうなっているか見てみましょう。std::string は std::basic_string<char> の別名で、basic_string の構造は少なくとも次のようになります。文字配列 CharT へのポインタ、現在の文字列長を表す size、コンテナの容量を表す capacity を持ちます。64bit x86 の環境なら、最低でも $8+8+8=24$ bytes は必要になります。
struct {
CharT* ptr;
size_type size;
size_type capacity;
};
ただし、string は単なるコンテナではありません。実際には短い文字列を扱うときに特別な最適化が入っており、これが Short String Optimization(Short String Optimization, SSO)です。
Quick C++ Benchmarks を使って、次のコードの実行結果を見てみましょう。
const char* SHORT_STR = "hello world";
void ShortStringCreation(benchmark::State& state) {
// 文字列を何度も生成する
// SSO の影響で新しいメモリ確保は不要
for (auto _ : state) {
std::string created_string(SHORT_STR);
// コンパイラの過度な最適化を防ぐために必要
benchmark::DoNotOptimize(created_string);
}
}
BENCHMARK(ShortStringCreation);
void ShortStringCopy(benchmark::State& state) {
// 文字列オブジェクトを 1 回だけ作り、何度も代入(コピー)する
std::string x; // create once
for (auto _ : state) {
x = SHORT_STR; // copy
benchmark::DoNotOptimize(x);
}
}
BENCHMARK(ShortStringCopy);
const char* LONG_STR = "this will not fit into small string optimization";
void LongStringCreation(benchmark::State& state) {
// 長い文字列はメモリ確保を引き起こす
for (auto _ : state) {
std::string created_string(LONG_STR);
benchmark::DoNotOptimize(created_string);
}
}
BENCHMARK(LongStringCreation);
void LongStringCopy(benchmark::State& state) {
// メモリを再利用するので、代入(コピー)の速度が向上する
std::string x;
for (auto _ : state) {
x = LONG_STR;
benchmark::DoNotOptimize(x);
}
}
BENCHMARK(LongStringCopy);
GCC 11.2 + libstdc++ を 64bit x86 の i3-10100 で動かすと、次の結果になります:
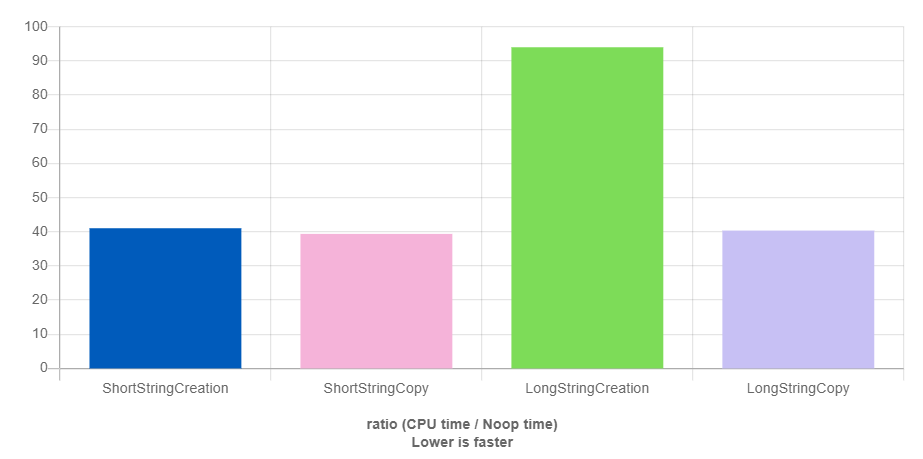
(図 1:GCC + libstdc++ における短文字列/長文字列の生成・コピー性能比較)
図 1 の縦軸は実行時間の相対値で、値が小さいほど速いことを意味します。短い文字列オブジェクトを生成するときは、長い文字列オブジェクトを生成するときよりも時間が短いことが分かります。主な理由は、string オブジェクト自体が小さな文字列配列の領域を内部に持っているためです。長い場合は概念的に次のようになり、短い場合はオブジェクト自身のスタック領域に直接格納し、長い場合はヒープメモリを確保して格納します。一般的にこの予約領域は 16 文字で、union を使って空間を節約するため、最終的に string のサイズが $8+8+16=32$ になるのが見えるようになります。
struct {
size_type size;
size_type capacity;
// union は最大サイズのメンバに合わせてメモリを確保する(ここでは 16)
union {
CharT* ptr;
std::array<char, 16> short_string;
}
};
コンパイラ(GCC / Clang)や標準ライブラリ実装(libstdc++ (GNU) / libc++ (LLVM))によって結果は多少変わり得ます。たとえば SSO の実装方式、メモリコピーの処理、オブジェクトの生成・破棄の扱いなどが異なるためです。差が気になる場合は、コンパイラのコンパイルロジックや標準ライブラリの実装(例:GCC のソース、LLVM のソース)を参照する必要があります。特に重要なのは、性能を推測するよりも、実際に一度走らせて測るのが一番確実だということです。
小さな実験で検証することもできます。次の example1.cc は string がヒープを使う状況を観察するのに使えます。
// example1.cc
#include <string>
#include <cstdio>
#include <cstdlib>
std::size_t allocated = 0;
void *operator new(size_t sz)
{
void *p = std::malloc(sz);
allocated += sz;
return p;
}
void operator delete(void *p) noexcept
{
return std::free(p);
}
int main()
{
allocated = 0;
std::string s("***"); // 短文字列
std::printf("stack space = %zu, heap space = %zu, capacity = %zu\n",
sizeof(s), allocated, s.capacity());
allocated = 0;
std::string s2(s.capacity() + 1, '*'); // 長文字列
std::printf("stack space = %zu, heap space = %zu, capacity = %zu\n",
sizeof(s2), allocated, s2.capacity());
allocated = 0;
s2.push_back('x');
std::printf("stack space = %zu, heap space = %zu, capacity = %zu\n",
sizeof(s2), allocated, s2.capacity());
}
Clang + libstdc++ での実行結果は次のとおりです:
$ clang++ -std=c++20 -stdlib=libstdc++ example1.cc; ./a.out
stack space = 32, heap space = 0, capacity = 15
stack space = 32, heap space = 17, capacity = 16
stack space = 32, heap space = 33, capacity = 32
最初の文字列は短いので、string 内部に予約された領域を使い、ヒープ使用量が 0 になっています。次に、2 つ目の文字列は長い(短文字列領域より 1 文字だけ多い)ため、new が呼ばれてヒープ確保が発生します。ヒープ使用量が capacity より 1 多いのは、末尾に終端文字(Terminal Null)\0 を追加するためです。さらに長文字列に対して push_back すると、std::vector と同じ仕組みで、容量を倍にした新しいヒープ領域を再確保します。
同じ実験を Clang + libc++ で行うと次のようになります:
$ clang++ -std=c++20 -stdlib=libc++ example1.cc; ./a.out
stack space = 24, heap space = 0, capacity = 22
stack space = 24, heap space = 32, capacity = 31
stack space = 24, heap space = 0, capacity = 31
興味深い結果です。libc++ の SSO 領域は 22 で、長文字列の場合は「ちょうど長文字列の長さ」を確保するのではなく、SSO を 1 文字だけ超える 23(22 + 1)であっても、ヒープでは長さ 32 を確保する実装になっています。実際、SSO の実装方法に絶対的な正解はなく、ライブラリや会社によって独自実装があり得ます。
興味があれば次の資料も参考にしてください:
