[Paper Review] Machine Learning at Facebook: Understanding Inference at the Edge
- 2020-10-21
- Liu, An-Chi 劉安齊
¶ Paper Information
Paper: Machine Learning at Facebook: Understanding Inference at the Edge
Author: Carole-Jean Wu et al.
Source: 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA)
¶ Review
Machine learning is now everywhere no matter on computers or mobile devices. Facebook has many services using machine learning or deep learning. To reduce the inference time is of importance to give a better user experience. However, it is quite challenging that the devices’ performances are various to design a one-for-all solution. This paper collects a lot of user datum and takes a data-driven approach to improve the inference on smartphones and edge devices.
 (In a median Android device, GPU provides only as much performance as its CPU. Only 11% of the smartphones have a GPU that is 3 times more performant than its CPU.)
(In a median Android device, GPU provides only as much performance as its CPU. Only 11% of the smartphones have a GPU that is 3 times more performant than its CPU.)
It takes a faster computing speed on GPU or DSP than CPU on computers. However, the biggest problem is that on median and low-end mobile devices, their GPUs aren’t powerful enough than CPUs. As the author mentions in the paper, only 11% of GPU on smartphones on the market take 3x performant than its CPU, which means we cannot offload the computation to accelerators to speed up the computation just like what we do on computers. What’s even worst, many smartphone vendors do not support GPU computing APIs, such as OpenCL, OpenGL, Vulkan, etc., which hinders the growth of the inference improvement of machine learning.

(Mobile GPUs have fragile usability and poor programmability.)
Luckily, we already have many machine learning tools on the market to take the horizontal-designed approach, for example, ONNX, TensorFlow Lite, Caffe 2, QNNPACk, etc., which all facilitate the development of machine learning on mobile devices. Those technologies enable Facebook Apps to run efficiently across a variety of mobile platforms, and so as to edge devices like VRs. On the other hand, some devices have better GPU or DSP so we can take the advantage of their computing power to accelerate DNN computing, but we still need to worry about the issues like quantization or memory layout.
In summary, the significant performance variability observed for mobile inference introduces varied user experiences. There are many challenges, including 1. Most inferences run on CPU at least six years ago and performance variety is a problem, 2. The performance between CPU and GPU/DSP is not great, 3. Accelerator computing APIs are not supported by some vendors, 4. The power consumption is much more important than the accuracy and speedup, 5. Accuracy is a priority but it comes with reasonable memory size. This paper gains a deeper understanding of the inference on mobile devices, and it helps guide the researcher to better design and evaluate DNN inference at the edge.
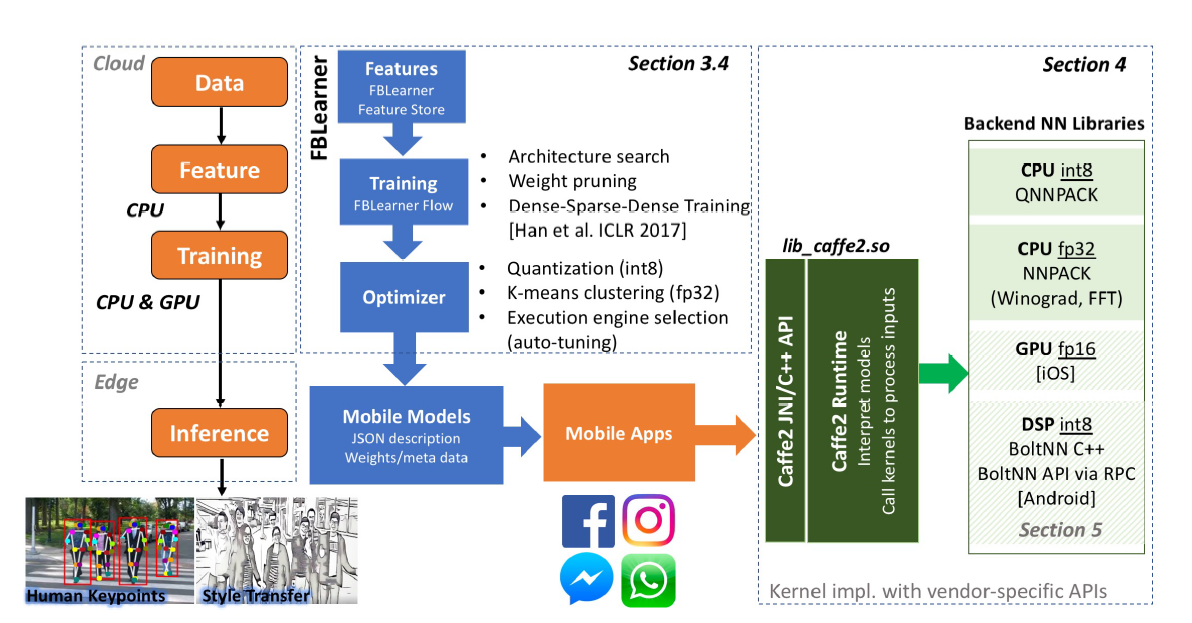
(Execution flow of Facebook’s machine learning for mobile inference.)
