C++ 短字串最佳化(Short String Optimization)
C++ 的 std::string 是我們在學 C++ 最早且最常使用的函示庫了,我們在學習的時候大多是去理解 string 就是一個容器(container),基本上大概可以想成 std::vector<char>。
我們看一下 std::string 裡面長什麼樣子,std::string 其實是 std::basic_string<char> 的別名,basic_string 結構至少會長的像以下程式碼,一個字元類別 CharT 的陣列指標,紀錄當前字串多長的 size,以及當前字串容器的容量 capacity,以跑在 64 bits x86 架構上來說,一個 string 起碼會需要 $8+8+8=24$ bytes。
struct {
CharT* ptr;
size_type size;
size_type capacity;
};
但實際上 string 不是簡單的容器而已,事實上他在處理短字串時會有特別的優化,也就是短字串最佳化(Short String Optimization, SSO)。
我們先用 Quick C++ Benchmarks 來看一下以下程式碼的執行結果。
const char* SHORT_STR = "hello world";
void ShortStringCreation(benchmark::State& state) {
// 不斷重新產生字串
// 因為短字串最佳化的關係,不需要分配新的記憶體
for (auto _ : state) {
std::string created_string(SHORT_STR);
// 必須加上這行來避免編譯器過度優化
benchmark::DoNotOptimize(created_string);
}
}
BENCHMARK(ShortStringCreation);
void ShortStringCopy(benchmark::State& state) {
// 產生字串物件一次,然後不斷重複複製
std::string x; // create once
for (auto _ : state) {
x = SHORT_STR; // copy
benchmark::DoNotOptimize(x);
}
}
BENCHMARK(ShortStringCopy);
const char* LONG_STR = "this will not fit into small string optimization";
void LongStringCreation(benchmark::State& state) {
// 長的字串會觸發記憶體分配的機制
for (auto _ : state) {
std::string created_string(LONG_STR);
benchmark::DoNotOptimize(created_string);
}
}
BENCHMARK(LongStringCreation);
void LongStringCopy(benchmark::State& state) {
// 重新使用記憶體,所以複製的話速度會有提升
std::string x;
for (auto _ : state) {
x = LONG_STR;
benchmark::DoNotOptimize(x);
}
}
BENCHMARK(LongStringCopy);
使用 GCC 11.2 + libstdc++ 跑在 64 bits x86 的 i3-10100 處理器上得到以下結果:
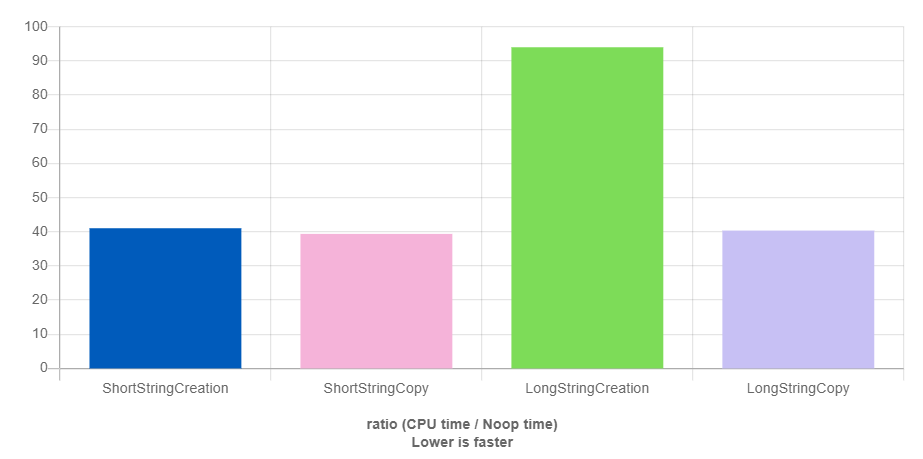
(圖一:使用 GCC + libstdc++ 短字串與長字串生成和複製的效能比較)
圖一縱軸是執行時間的相對時間,數值越低代表越快,可以發現 string 在生成短字串物件的時候花費時間比生成長字串物件來的短,其主要原因是 string 物件本身帶有一個預存小的字串陣列空間,長的可能會像以下示例程式碼,當字串很短的時候就直接用物件本身的 stack,就可以很快的將字串儲存起來,反之如果要儲存長的字串的時候再去宣告 heap 記憶體空間來使用。通常字串預留空間都是 16 長度,並且會使用 union 來省空間,所以之後可以看到一個 string 佔的空間會是 $8+8+16=32$。
struct {
size_type size;
size_type capacity;
// union 取其最大 size 的物件為記憶體 size,這邊為 16
union {
CharT* ptr;
std::array<char, 16> short_string;
}
};
根據編譯器的不同(GCC 或 Clang)以及標準函示庫的實作不同(libstdc++ (GNU) 或 libc++ (LLVM)),結果都可能會多少有差,例如 SSO 的實作方式,記憶體複製的操作,物件建構和解構的處理等等。產生差異的話,可能要參考編譯器的編譯邏輯以及標準函示庫實作(gcc 原始碼 或 llvm 原始碼)。特別注意,與其猜測程式效能,實際跑一遍看最準!
我們也可以跑個小實驗驗證一下,以下 example1.cc 可以用來觀察 string 使用 heap 的情況。
// example1.cc
#include <string>
#include <cstdio>
#include <cstdlib>
std::size_t allocated = 0;
void *operator new(size_t sz)
{
void *p = std::malloc(sz);
allocated += sz;
return p;
}
void operator delete(void *p) noexcept
{
return std::free(p);
}
int main()
{
allocated = 0;
std::string s("***"); // 短字串
std::printf("stack space = %zu, heap space = %zu, capacity = %zu\n",
sizeof(s), allocated, s.capacity());
allocated = 0;
std::string s2(s.capacity() + 1, '*'); // 長字串
std::printf("stack space = %zu, heap space = %zu, capacity = %zu\n",
sizeof(s2), allocated, s2.capacity());
allocated = 0;
s2.push_back('x');
std::printf("stack space = %zu, heap space = %zu, capacity = %zu\n",
sizeof(s2), allocated, s2.capacity());
}
使用 Clang + libstdc++ 的執行結果如下:
$ clang++ -std=c++20 -stdlib=libstdc++ example1.cc; ./a.out
stack space = 32, heap space = 0, capacity = 15
stack space = 32, heap space = 17, capacity = 16
stack space = 32, heap space = 33, capacity = 32
第一個字串物件因為是短字串,所以直接使用 string 裡面預留的空間,因此可以看到 heap 使用空間為 0。接著第二個字串存的是一個長字串(比短字串的空間再多一個),所以 string 觸發 new 去分配新的 heap 來儲存字串,可以發現 heap 空間比 capacity 多一個,這是因為實際上最後還會補上一個終止符號(Terminal Null)\0。當我們在長字串後面 push_back 一個字元時,其機制跟 std::vector 一樣,會重新分配兩倍大的 heap 來作為新的預留空間。
同樣的實驗我們換成 Clang + libc++ 跑跑看:
$ clang++ -std=c++20 -stdlib=libc++ example1.cc; ./a.out
stack space = 24, heap space = 0, capacity = 22
stack space = 24, heap space = 32, capacity = 31
stack space = 24, heap space = 0, capacity = 31
可以看到很有意思的結果,libc++ 的 SSO 空間是 22,然後如果是長字串的話,不是直接分配剛好等於長字串的長度,即使長字串是剛好超過 SSO 的 23(22 + 1),libc++ 的實作中就直接讓 heap 去分配 32 的長度。事實上,SSO 的實作方式沒有絕對的作法,不同函示庫甚至不同公司可能都有自己的實作。
有興趣的話可以參考以下資料:
